用Colab Pro+和Google Cloud Storage低成本训练600M参数的模型
Table of Contents
介绍一个实用的小参数量模型训练方案:通过Google Colab Pro+提供计算能力、Google Cloud Storage(GCS)存储数据,用1万小时语音数据低成本训练一个600M参数的文本到语音 (TTS) 模型 parler-tts-mini-v0.1。在这篇文章中,我会详细说明每个具体步骤,包括一些踩过的坑。
核心工具:Colab Pro+与Google Cloud Storage Link to this section
为什么选择这个组合?这套方案是在多次实验后,认为是兼顾性能、成本和灵活性的最优解。
Colab Pro+: 可以用相对低廉的订阅价格,按需获得强大的计算资源,目前最好的卡是NVIDIA A100 40GB。对于600M参数的模型来说,这个卡已经相当不错。
Google Cloud Storage (GCS): Colab本地的存储空间是临时的,且容量有限。对于动辄几TB的数据集、模型和检查点(checkpoints),GCS是理想的解决方案。它提供了可扩展、持久化且高速的存储。
- 为什么不用 Google Drive? 虽然方便,但在处理大规模训练数据时,它的读写速度和潜在的流量限制可能会成为瓶颈,严重影响训练效率,甚至导致I/O卡死。更严重的问题是:写入Google Drive的数据会在本地磁盘缓存,造成本地磁盘空间耗尽。Google Drive的具体限制信息:https://developers.google.com/workspace/drive/api/guides/limits
创建并配置GCS bucket Link to this section
首先,需要一个GCS bucket来存放所有数据:
创建GCS bucket:前往 https://console.cloud.google.com/storage/create-bucket 创建一个新的 bucket,建议使用Standard存储类型,没有最短存储时间限制。
选择正确的存储位置(Region):为了实现最低的延迟和最快的读写速度,必须确保GCS bucket和Colab运行时在同一个地理区域,建议选择北美地区,费用相对亚洲地区便宜。这可能是整个流程中最容易被忽视但影响最大的细节。不要开通Multi-region,流量费用较高(后面会介绍这个“坑”)。
设置软删除保留时长为0天:软删除政策促销已经结束,删除后7天内仍然要收费(由于官方文档说法不一致,暂且假定促销已结束)。
可以通过 https://console.cloud.google.com/storage/browser 浏览GCS bucket中的文件。
创建GCS bucket之后,每次创建一个新Colab虚拟机,都要确认虚拟机位置和GCS bucket位置在同一个大区域(比如北美、亚洲、欧洲等)。跨区域访问(例如,从新加坡的Colab访问美国的bucket)会极大地拖慢读写bucket数据速度。
可以在Colab的终端中运行以下命令,查看当前分配的虚拟机所在位置:
curl ipinfo.io输出会类似这样,说明Colab虚拟机位于北美(Iowa):
{
"ip": "34.41.222.46",
"hostname": "46.222.41.34.bc.googleusercontent.com",
"city": "Council Bluffs",
"region": "Iowa",
"country": "US",
"loc": "41.2619,-95.8608",
"org": "AS396982 Google LLC",
"postal": "51502",
"timezone": "America/Chicago",
"readme": "https://ipinfo.io/missingauth"
}在Colab中挂载GCS bucket Link to this section
创建好bucket后,需要用gcsfuse工具将其像本地磁盘一样挂载到Colab环境中:
# 1. 用户授权
from google.colab import auth
auth.authenticate_user()
# 2. 安装 gcsfuse
!echo "deb https://packages.cloud.google.com/apt gcsfuse-`lsb_release -c -s` main" | sudo tee /etc/apt/sources.list.d/gcsfuse.list
!curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
!apt -qq update && apt -qq install gcsfuse
# 3. 挂载 bucket
# 将 "my-gcs-bucket1" 替换为你的bucket名称
gcs_bucket_name = "my-gcs-bucket1"
local_mount_path = f"/mnt/gs/{gcs_bucket_name}"
!mkdir -p {local_mount_path}
# 使用优化参数挂载,提升数据加载性能
!gcsfuse --implicit-dirs --type-cache-max-size-mb=-1 --stat-cache-max-size-mb=-1 --kernel-list-cache-ttl-secs=-1 --metadata-cache-ttl-secs=-1 {gcs_bucket_name} {local_mount_path}
# 4. 验证挂载是否成功
!ls -lh {local_mount_path}gcsfuse 性能提示:上述挂载命令中 -1 的设置意味着“无限制”,让gcsfuse尽可能多地使用内存来缓存文件元数据,这对于需要反复读取大量小文件的训练任务能极大地提升性能。
gcsfuse CLI提供了多种可配置选项,详细信息请参见 gcsfuse CLI 。使用某些选项,例如在 Overview of caching in Cloud Storage FUSE 中描述的缓存功能,可以提高读取性能并降低成本。例如,MaxText设置了gcsfuse参数(MaxText gcsfuse设置链接)来减少训练时的数据加载时间。
一步步训练600M模型 Link to this section
环境就绪,现在开始真正的训练流程。
克隆代码库并安装依赖 Link to this section
# 设置环境变量以优化tokenizer的并行处理
import os
os.environ["TOKENIZERS_PARALLELISM"] = "true"
# 克隆parler-tts代码库
%cd /content
!git clone https://github.com/huggingface/parler-tts.git
# 安装依赖
%cd parler-tts
!ls
!pip install -e .[train]
!pip install flash-attn --no-build-isolation配置 accelerate
Link to this section
# 设置Huggingface缓存目录,避免预训练模型占满磁盘空间
%env HF_HOME=/mnt/gs/my-gcs-bucket1/parler-tts/huggingface_cache
!accelerate configColab使用单块 GPU 进行训练。它会以问答形式配置,依次选择:
In which compute environment are you running?
This machineWhich type of machine are you using?
No distributed trainingDo you want to run your training on CPU?
NoHow many GPUs should be used for distributed training?
1Do you want to use DeepSpeed?
NoWhat GPUs should be used for training on this machine as a comma-separated list?
allDo you wish to use FP16 or BF16 (mixed precision)?
bf16
bf16 是 A100 GPU 支持的一种混合精度格式,可以在不牺牲太多精度的情况下,大幅提升训练速度并降低显存占用。
初始化模型与配置训练 Link to this section
运行官方脚本,创建一个未经训练的模型结构。所有路径都指向之前挂载的GCS目录:
# 设置Huggingface缓存目录,避免预训练模型占满磁盘空间
%env HF_HOME=/mnt/gs/my-gcs-bucket1/parler-tts/huggingface_cache
# 运行初始化脚本
%cd /content/parler-tts/
!python helpers/model_init_scripts/init_model_600M.py \
/mnt/gs/my-gcs-bucket1/parler-tts/parler-tts-untrained-600M \
--text_model google/flan-t5-base \
--audio_model parler-tts/dac_44khZ_8kbps将官方的600M参数模型训练配置文件starting_point_0.01.json复制一份为starting_point_0.01_colab.json,并根据Colab进行修改。关键修改点如下:
路径: 将所有文件路径(模型、缓存、数据集、输出目录等)全部指向 GCS 挂载点,例如
/mnt/gs/my-gcs-bucket1/parler-tts/…。dataloader_num_workers: 指定从GCS bucket读取数据的并行线程数。设置为8是一个较好的平衡点,能有效利用CPU,又不会因为过多的并行读取请求而使gcsfuse阻塞。resume_from_checkpoint:如果训练中断,从一个检查点继续训练,可以通过这个参数指定保存在bucket上的检查点位置。
{
"model_name_or_path": "/mnt/gs/my-gcs-bucket1/parler-tts/parler-tts-untrained-600M/parler-tts-untrained-600M/",
"cache_dir": "/mnt/gs/my-gcs-bucket1/parler-tts/huggingface_cache/",
"save_to_disk": "/mnt/gs/my-gcs-bucket1/parler-tts/tmp_dataset_audio/",
"temporary_save_to_disk": "/mnt/gs/my-gcs-bucket1/parler-tts/audio_code_tmp/",
"resume_from_checkpoint": "/mnt/gs/my-gcs-bucket1/parler-tts/output_dir_training/checkpoint-200000-epoch-1/",
"feature_extractor_name":"ylacombe/dac_44khZ_8kbps",
"description_tokenizer_name":"google/flan-t5-base",
"prompt_tokenizer_name":"google/flan-t5-base",
"report_to": ["wandb"],
"overwrite_output_dir": true,
"output_dir": "/mnt/gs/my-gcs-bucket1/parler-tts/output_dir_training",
"train_dataset_name": "blabble-io/libritts_r+blabble-io/libritts_r+blabble-io/libritts_r+parler-tts/mls_eng_10k",
"train_metadata_dataset_name": "parler-tts/libritts_r_tags_tagged_10k_generated+parler-tts/libritts_r_tags_tagged_10k_generated+parler-tts/libritts_r_tags_tagged_10k_generated+parler-tts/mls-eng-10k-tags_tagged_10k_generated",
"train_dataset_config_name": "clean+clean+other+default",
"train_split_name": "train.clean.360+train.clean.100+train.other.500+train",
"eval_dataset_name": "blabble-io/libritts_r+parler-tts/mls_eng_10k",
"eval_metadata_dataset_name": "parler-tts/libritts_r_tags_tagged_10k_generated+parler-tts/mls-eng-10k-tags_tagged_10k_generated",
"eval_dataset_config_name": "other+default",
"eval_split_name": "test.other+test",
"target_audio_column_name": "audio",
"description_column_name": "text_description",
"prompt_column_name": "text",
"max_eval_samples": 96,
"max_duration_in_seconds": 30,
"min_duration_in_seconds": 2.0,
"max_text_length": 400,
"group_by_length": true,
"add_audio_samples_to_wandb": true,
"id_column_name": "id",
"preprocessing_num_workers": 1,
"do_train": true,
"num_train_epochs": 40,
"gradient_accumulation_steps": 8,
"gradient_checkpointing": false,
"per_device_train_batch_size": 3,
"learning_rate": 0.00095,
"adam_beta1": 0.9,
"adam_beta2": 0.99,
"weight_decay": 0.01,
"lr_scheduler_type": "constant_with_warmup",
"warmup_steps": 20000,
"logging_steps": 1000,
"freeze_text_encoder": true,
"do_eval": true,
"predict_with_generate": true,
"include_for_metrics": true,
"evaluation_strategy": "steps",
"eval_steps": 10000,
"save_steps": 10000,
"save_total_limit": 10,
"per_device_eval_batch_size": 6,
"audio_encoder_per_device_batch_size": 8,
"dtype": "bfloat16",
"seed": 456,
"dataloader_num_workers": 8,
"attn_implementation": "sdpa"
}开始训练模型 Link to this section
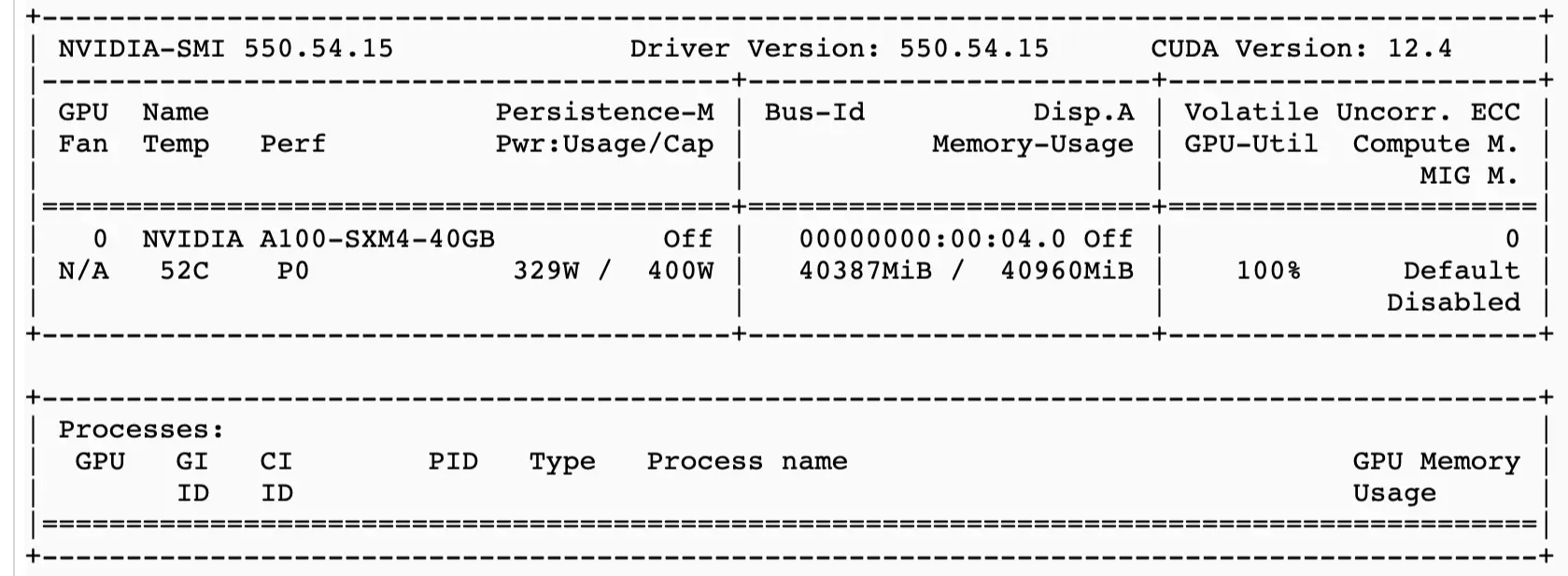
!accelerate launch training/run_parler_tts_training.py helpers/training_configs/starting_point_0.01_colab.json通过nvidia-smi跟踪显卡使用情况,
如果训练卡顿,也可以通过dool等工具检查是否是网络问题(见文末)。
Colab Pro+会话有大约24小时的连续运行限制。之后连接会中断,需要重新申请资源、重新安装依赖。但好在所有的数据和检查点都保存在GCS上,通过配置resume_from_checkpoint可以从最近的检查点继续训练。
GCS成本分析与优化 Link to this section
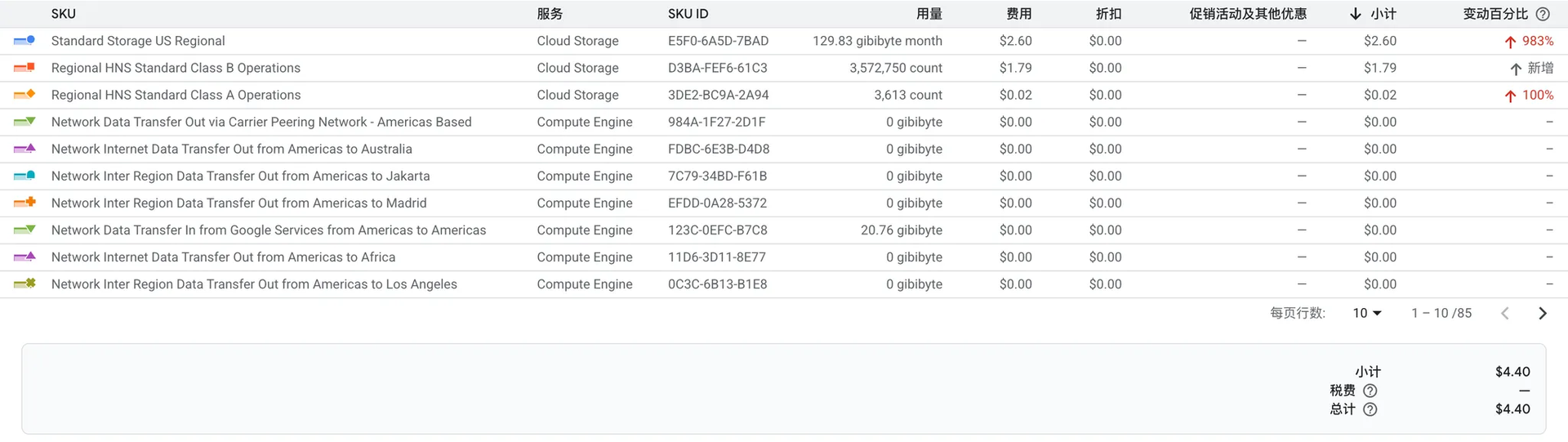
使用云服务,成本是最大的问题。下面这张账单截图暴露了一个常见的错误配置。

可以看到,费用大头来自Network Data Transfer GCP Replication within Northern America。
这是什么费用? 这意味着我创建的 GCS bucket 是多区域 (Multi-region)类型。当向其中写入数据时(比如保存模型checkpoint),GCS 会自动将数据复制到北美洲的多个不同数据中心,以实现高可用性和灾备。这个复制过程产生了网络传输费用。
如何优化? 对于这种单点训练的场景,并不需要多区域的高可用特性。将bucket类型从Multi-region改为Regional,就可以完全消除这部分复制费用。
设置预算提醒:为避免意外产生高额费用,可以在Google Cloud Console的“结算→预算和提醒”页面创建一个预算。例如,当费用达到50美元时发送邮件提醒。
GCS使用成本 Link to this section
Colab Pro+配合GCS一周的使用费用很低,主要是存储和B类操作,
另外,Colab访问GCS的流量是免费的。
如何迁移bucket Link to this section
如何将bucket从multi-region迁移到regional:Transfer between Cloud Storage buckets
对于小于1TB的数据,执行以下步骤:
# 选择项目
gcloud projects list
gcloud config set project project_name
# 开始拷贝数据
gcloud transfer jobs create \
gs://source_bucket \
gs://destination_bucket如果遇到权限问题:
ERROR: (gcloud.transfer.jobs.create) FAILED_PRECONDITION: Failed to obtain the location of the GCS bucket my-gcs-bucket1 Additional details: project-xxxxxxxxxxxxx@storage-transfer-service.iam.gserviceaccount.com does not have storage.buckets.get access to the Google Cloud Storage bucket. Permission 'storage.buckets.get' denied on resource (or it may not exist).需要先添加权限:
gcloud transfer authorize --add-missing查看拷贝进度:https://console.cloud.google.com/transfer/jobs/
实用技巧与监控 Link to this section
Colab终端tmux Link to this section
Colab自带的终端功能非常强大,它实际上是一个tmux会话,学会几个基本快捷键。tmux的所有快捷键都需要先按下一个“前缀”组合键 Ctrl+b,然后再按下一个功能键。
Ctrl+b然后c:创建一个新的终端窗口Ctrl+b然后n:切换到下一个窗口Ctrl+b然后p:切换到上一个窗口Ctrl+b然后%: 水平分割当前窗口Ctrl+b然后": 垂直分割当前窗口 (pane)Ctrl+b然后方向键: 在分割的窗格之间移动
利用这些快捷键,可以一边开着nvidia-smi监控显卡,一边执行其他命令,非常方便。
监控网络和I/O Link to this section
如果感觉训练速度不理想,需要排查是计算瓶颈还是I/O瓶颈。
# 监控本地磁盘
apt install sysstat
iostat -x 1
# 监控网络和本地磁盘
pip install dool
dool -cdngyltm --disk-util --disk-tps --fs 1在dool的输出中,dsk/total下的read和writ列显示了磁盘读写速度,net/total的recv和send显示了网络收发速度,可以快速定位瓶颈。

磁盘空间监测 Link to this section
如果发现磁盘空间迅速被占满,可以看看是不是huggingface预训练模型或者数据下载到/root/,而不是放在GCS bucket上,列出所有超过100MB的文件:
find /root/ -type f -size +100M -exec ls -lh {} \;统计根目录下每个目录占用的空间,
sudo du -h --max-depth=1 --exclude=/proc --exclude=/sys --exclude=/dev --exclude=/run --exclude=/mnt /总结 Link to this section
通过Colab Pro+和GCS的强强联合,成功搭建了一个经济高效的模型训练环境。关键要点:
Colab Pro+提供A100 40GB,GCS提供存储
务必确保Colab VM和GCS bucket在同一区域
GCS不要使用multi-region,并设置预算提醒
将huggingface预训练模型、数据、模型检查点等保存在GCS上
使用
tmux和dool等工具,监控系统效率,快速发现瓶颈