用LitData Viewer查看LitData分片内容
Contents
最近从WebDataset切换到LitData,LitData是PyTorch Lightning同公司开发的,刚发布的时候我就尝试过,当时bug比较多就放弃了。经过一年多的迭代,已经非常强大。而且它和PyTorch Lightning框架解耦,可以单独在任意训练/推理pipeline中使用。支持读取多种shards:LitData格式、HF Parquet格式、MosaicML格式,还可以通过StreamingRawDataset直接在原始数据上实现流式。
相对WebDataset的tar分片文件,LitData的缺点是打包生成的bin分片(有时还是 zstd 压缩)可读性差,无法像tar文件那样直接读取内容。这些.bin内部有完整结构,但没有任何文件名和目录概念,也没有现成的CLI用眼睛检查一下数据。在调试数据预处理、排查label错误或查看某个样本的实际图片/音频时,这种看不见摸不着的感觉非常影响效率。
我开源了一个工具LitData Viewer,一个专门用来查看LitData分片的桌面工具。
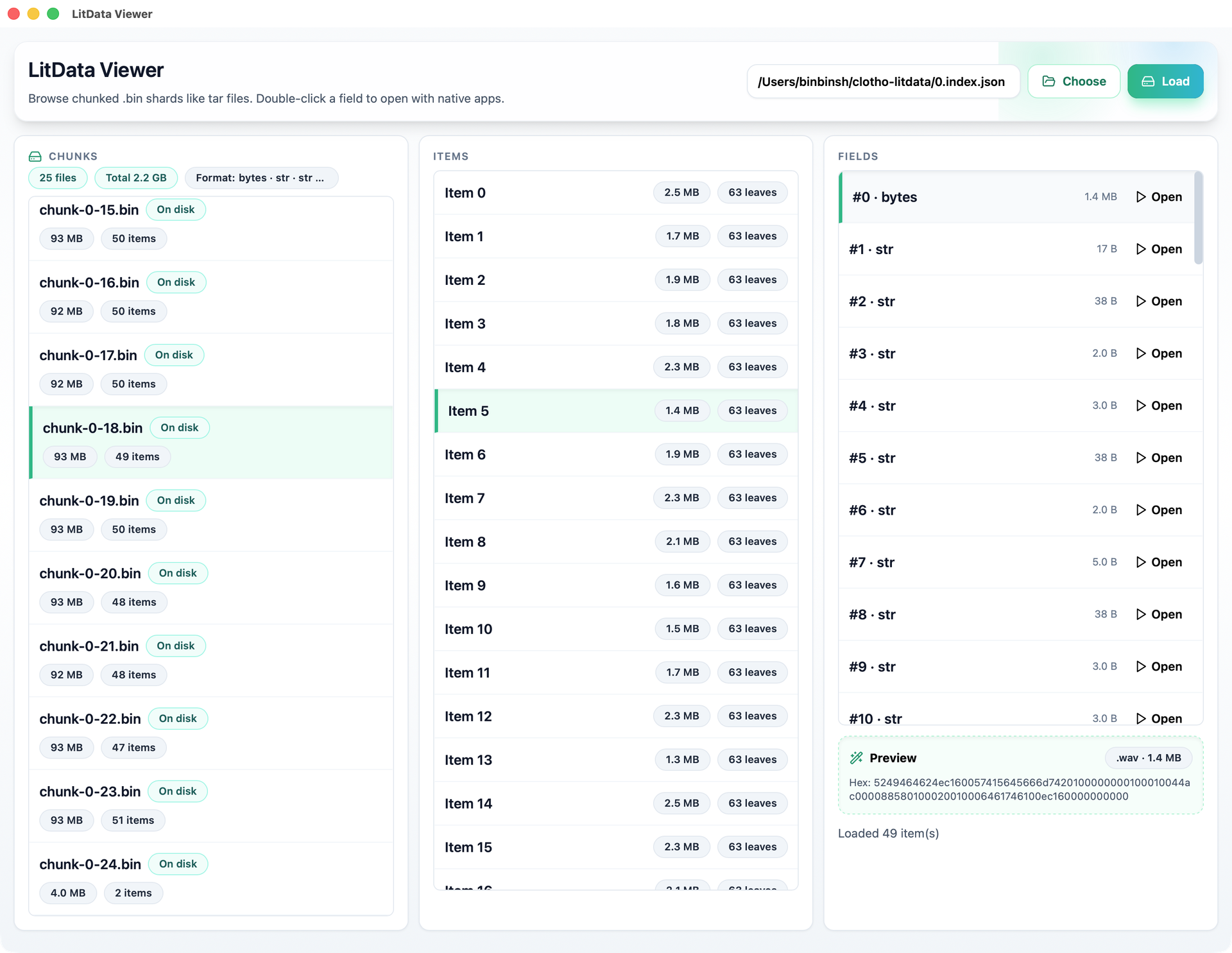
LitData 的分片结构 Link to this section
下面介绍 LitData 的数据分片格式,以及 Viewer 是如何读取这些数据的。
index.json 文件 Link to this section
index.json 是 LitData 的核心配置文件,它包含:
数据配置信息 (config)
- compression:压缩方式,通常是null或zstd
- chunk_size:每个分片文件包含多少条数据
- chunk_bytes:每个分片文件的目标大小
- data_format:数组,说明每条数据有哪些字段
- data_spec:字段的含义说明
分片列表 (chunks)
- 每个分片包含:
- filename:文件名(如
0.bin) - chunk_bytes:文件大小
- chunk_size:包含多少条数据
- dim:tensor 的维度信息(部分场景使用)
- filename:文件名(如
- 每个分片包含:
.bin 文件的内部结构
Link to this section
一个未压缩的 LitData 分片文件结构是这样的:
u32 num_items // 数据条数 N
u32 offsets[num_items + 1] // N+1 个位置信息
// 每条数据 i (0 到 N-1):
u32 field_sizes[字段数量] // 每个字段的大小
u8 字段_0[field_sizes[0]]
u8 字段_1[field_sizes[1]]
...
u8 字段_k[field_sizes[k-1]]如果文件是用 zstd 压缩的,文件后缀是 .bin.zst,整个文件都是压缩的。无法直接跳到某个位置,所以 Viewer 的做法是:第一次打开文件时,把整个文件解压到内存,保存在缓存里。之后的所有操作都在内存中进行,如果文件没有压缩,可以直接跳到任意位置读取,不需要全部加载到内存。
判断文件类型和打开方式 Link to this section
为了能够让 Viewer 直接打开.bin文件中的数据,比如用Adobe Audition打开某个.wav文件。我添加了自动文件类型识别,并根据识别的文件类型,使用系统默认的程序打开。
文件类型识别 Link to this section
首先,根据 data_format 确定每条数据包含几个字段,再推断文件扩展名:
常见类型直接映射:
png → .png、jpeg/jpg → .jpg、str/string → .txt等复杂格式解析:
some.custom.ext取最后一段检查文件内容特征:当 data_format 为
bytes或bin时,通过检测文件头特征(如 RIFF、WAVE、ID3、fLaC)或文本解析来判断实际类型
通过默认程序打开 Link to this section
选中字段后,可以在预览区查看内容,双击字段会自动生成临时文件保存在 /tmp 目录下,并使用系统默认的应用程序打开这个字段的数据。
参考资料 Link to this section
Lightning-AI/litData:https://github.com/Lightning-AI/litData